El aumento de las sanciones relacionadas con la exposición de datos sensibles es cada vez mayor. Por ejemplo, las violaciones graves del GDPR pueden costar a las empresas hasta el 4% de su facturación global anual, mientras que las violaciones graves del HIPAA pueden resultar en prisión.
Es posible que tu entorno productivo esté completamente protegido. ¿Pero qué pasa con las iniciativas de testing y las demos de ventas? ¿Confías en los contratistas que tienen acceso a tus datos sensibles? ¿Harán todo lo posible para protegerlos?
Para garantizar el cumplimiento normativo y la seguridad de los datos, las empresas están recurriendo a proveedores de servicios de gestión de datos. Consulta esta guía que responde a las tres preguntas importantes:
- ¿Qué es el enmascaramiento de datos?
- ¿Por qué y cuándo se necesita?
- ¿Cómo podrías implementarlo con éxito en tu empresa?
Después de leer el artículo, tendrás suficiente información para negociar con proveedores de enmascaramiento de datos.
Comprender el enmascaramiento de datos
Entonces, ¿qué es el enmascaramiento de datos?
El enmascaramiento de datos es la creación de una versión realista pero falsa de los datos de la organización, manteniendo una estructura similar. Altera los valores de los datos originales utilizando técnicas de manipulación mientras mantiene el mismo formato, y ofrece una nueva versión que no se puede realizar mediante ingeniería inversa ni rastrear hasta los valores auténticos. Este es un ejemplo de datos enmascarados:
Para determinar si es necesario aplicar algoritmos de enmascaramiento de datos a todos tus datos almacenados, la respuesta es muy probablemente no. A continuación, se presentan los tipos de datos que definitivamente debes proteger:
- Protected Health Information (PHI) incluye registros médicos, pruebas de laboratorio, información sobre seguros médicos e incluso datos demográficos.
- La información de tarjetas de pago se refiere a la información de crédito y débito de las tarjetas y los datos de las transacciones según el Estándar de Seguridad de Datos de la Industria de Tarjetas de Pago (PCI DSS).
- La información de identificación personal (PII), como los números de pasaporte y de seguridad social. Básicamente, cualquier información que pueda ser utilizada para identificar a una persona.
- La propiedad intelectual (IP) incluye invenciones, como diseños, o cualquier cosa que tenga valor para la organización y pueda ser robada.
¿Por qué se necesita el enmascaramiento de datos?
El enmascaramiento de datos protege la información sensible utilizada para fines no productivos. Por lo tanto, siempre que utilices cualquiera de los tipos de datos sensibles presentados en la sección anterior en entrenamiento, pruebas, demostraciones de ventas o cualquier otro tipo de actividades no productivas, necesitas aplicar técnicas de enmascaramiento de datos. Esto tiene sentido ya que los entornos no productivos normalmente están menos protegidos e introducen más vulnerabilidades de seguridad.
Además, si necesitas compartir tus datos con proveedores y socios externos, puedes otorgar acceso a datos enmascarados en lugar de obligar a la otra parte a cumplir con tus medidas de seguridad extensivas para acceder a la base de datos original. Las estadísticas muestran que el 19% de las violaciones de datos ocurren debido a compromisos en el lado del socio comercial.
Además, el enmascaramiento de datos puede proporcionar las siguientes ventajas:
- Hace que los datos de la organización sean inútiles para los ciberdelincuentes en caso de que puedan acceder a ellos.
- Reduce los riesgos derivados de compartir datos con usuarios autorizados y proyectos de outsourcing.
- Ayuda a cumplir con las regulaciones relacionadas con la privacidad y seguridad de los datos, como el Reglamento General de Protección de Datos (GDPR), la Ley de Portabilidad y Responsabilidad del Seguro de Salud (HIPAA) y cualquier otra regulación aplicable dentro de tu campo.
- Protege los datos en caso de eliminación, ya que los métodos convencionales de eliminación de archivos aún dejan un rastro de los valores antiguos de los datos.
- Salvaguarda tus datos en caso de transferencia de datos no autorizada.
Tipos de enmascaramiento de datos
Existen cinco tipos principales de enmascaramiento de datos que buscan cubrir diferentes necesidades organizacionales.
1. Enmascaramiento de datos estático
Implica crear una copia de seguridad de los datos originales y mantenerla segura en un entorno separado para casos de uso de producción. Luego, disfraza la copia incluyendo valores falsos pero realistas, y la hace disponible para fines no productivos (por ejemplo, pruebas, investigación), así como para compartir con contratistas.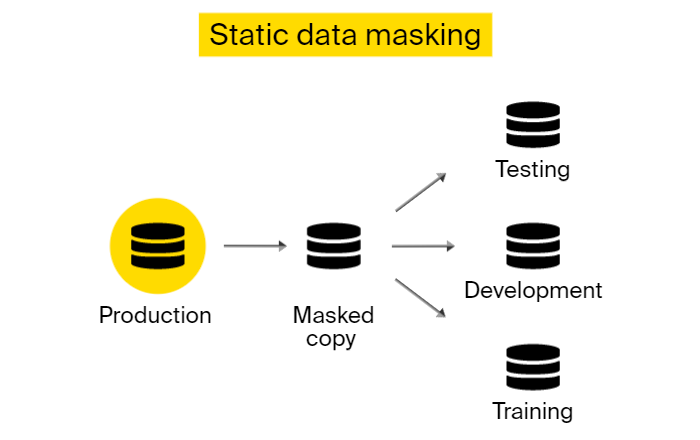
2. Enmascaramiento de datos dinámico
Este tipo de enmascaramiento tiene como objetivo modificar un fragmento de los datos originales en tiempo de ejecución cuando se recibe una consulta a la base de datos. Por lo tanto, cuando un usuario no está autorizado para ver información sensible, realiza una consulta a la base de datos de producción, y la respuesta se enmascara en tiempo real sin cambiar los valores originales. Esto se puede implementar a través de un proxy de base de datos, como se presenta a continuación. Normalmente se utiliza en entornos de solo lectura para evitar la anulación de los datos de producción.
3. Enmascaramiento de datos sobre la marcha
Este tipo de enmascaramiento de datos disfraza los datos al transferirlos de un entorno a otro, como de producción a pruebas. Es popular entre las organizaciones que realizan implementaciones continuas de software y grandes integraciones de datos.
4. Enmascaramiento de datos determinístico
Reemplaza los datos de una columna con un valor fijo. Por ejemplo, si deseas reemplazar “Olivia” con “Emma”, debes hacerlo en todas las tablas asociadas, no solo en la tabla que estás enmascarando.
5. Ofuscación de datos estadísticos
Se utiliza para revelar información sobre patrones y tendencias en un conjunto de datos sin compartir detalles sobre las personas reales representadas allí.
7 técnicas principales de enmascaramiento de datos
A continuación, puedes encontrar siete de las técnicas de enmascaramiento de datos más populares. Puedes combinarlas para cubrir las diversas necesidades de tu negocio.
- Shuffling. Puedes mezclar y reasignar los valores de datos dentro de la misma tabla. Por ejemplo, si mezclas la columna de nombres de los empleados, obtendrás los detalles personales reales de un empleado emparejados con los de otro.
- Scrambling. Rearma caracteres y enteros de un campo de datos en un orden aleatorio. Si el ID original de un empleado es 97489376, después de aplicar el scrambling, obtendrás algo como 37798649. Esto está restringido a tipos de datos específicos.
- Nulling out. Esta es una estrategia de enmascaramiento simple donde un campo de datos se le asigna un valor nulo. Este método tiene un uso limitado ya que tiende a fallar en la lógica de la aplicación.
- Substitution. Los datos originales son reemplazados por valores falsos pero realistas. Lo que significa que el nuevo valor aún debe cumplir con todas las restricciones del dominio. Por ejemplo, se puede sustituir el número de tarjeta de crédito de alguien con otro número que cumpla con las reglas impuestas por el banco emisor.
- Number variance. Esto se aplica principalmente a la información financiera. Un ejemplo es enmascarar los salarios originales aplicando una variación de +/- 20%.
- Date aging. Este método aumenta o disminuye una fecha en un rango específico, manteniendo que la fecha resultante cumpla con las restricciones de la aplicación. Por ejemplo, se pueden envejecer todos los contratos en 50 días.
- Averaging. Implica reemplazar todos los valores de datos originales por un promedio. Por ejemplo, se puede reemplazar cada campo de salario individual por un promedio de los valores salariales en esta tabla.
¿Cómo implementar el enmascaramiento de datos de manera adecuada?
Aquí te presentamos un plan de implementación de enmascaramiento de datos en 5 pasos.
Paso 1: Determinar el alcance del proyecto
Antes de empezar, es necesario identificar qué aspectos se cubrirán. A continuación, se presenta una lista de preguntas típicas que puede estudiar tu equipo de datos antes de continuar con las iniciativas de enmascaramiento:
- ¿Qué datos queremos enmascarar?
- ¿Dónde residen?
- ¿Quién está autorizado para acceder a ellos?
- ¿Cuál es el nivel de acceso de cada usuario de los anteriores puntos?
- ¿Quién puede ver solamente y quién puede modificar y eliminar valores?
- ¿Qué aplicaciones utilizan estos datos sensibles?
- ¿Qué impacto tendrá el enmascaramiento de datos en diferentes usuarios?
- ¿Qué nivel de enmascaramiento se requiere y con qué frecuencia necesitaremos repetir el proceso?
- ¿Estamos buscando aplicar el enmascaramiento de datos en toda la organización o limitarlo a un producto específico?
Paso 2: Definir la pila de técnicas de enmascaramiento de datos
Durante este paso, se debe identificar qué técnica o combinación de herramientas de enmascaramiento de datos se adapta mejor a la tarea en cuestión.
En primer lugar, se debe identificar qué tipos de datos se necesitan enmascarar, por ejemplo, nombres, fechas, datos financieros, etc., ya que los diferentes tipos requieren algoritmos de enmascaramiento de datos dedicados. En base a ello, se puede elegir qué biblioteca(s) de código abierto pueden reutilizarse para producir la solución de enmascaramiento de datos más adecuada. Aconsejamos que acudas a un proveedor de software, ya que te ayudará a personalizar la solución e integrarla sin problemas en tus flujos de trabajo en toda la empresa sin interrumpir ningún proceso empresarial. También es posible construir algo desde cero para cubrir las necesidades únicas de la empresa.
Existen herramientas de enmascaramiento de datos preconfiguradas que puedes adquirir e implementar por tí mismo, como Oracle Data Masking, IRI FieldShield, DATPROF, y muchas más. Puedes optar por esta estrategia si gestionas todos tus datos por tí mismo, entiendes cómo funcionan los diferentes flujos de datos y tienes un departamento de TI que pueda ayudar a integrar esta nueva solución de enmascaramiento de datos en los procesos existentes sin obstaculizar la productividad.
Paso 3: Asegura tus algoritmos de enmascaramiento de datos seleccionados
La seguridad de tus datos sensibles depende en gran medida de la seguridad de los algoritmos de generación de datos falsos seleccionados. Por lo tanto, solo el personal autorizado puede saber qué algoritmos de enmascaramiento de datos están implementados, ya que estas personas pueden desenmascarar los datos para obtener el conjunto de datos original con este conocimiento. Es una buena práctica aplicar la separación de deberes. Por ejemplo, el departamento de seguridad selecciona los algoritmos y herramientas más adecuados, mientras que los propietarios de los datos mantienen las configuraciones aplicadas en el enmascaramiento de sus datos.
Paso 4: Manten la integridad referencial
La integridad referencial significa que cada tipo de datos dentro de tu organización se enmascara de la misma manera. Esto puede ser un desafío si la organización es bastante grande y tiene varias funciones empresariales y líneas de productos. En este caso, es probable que la empresa utilice diferentes algoritmos de enmascaramiento de datos para varias tareas.
Para superar este problema, es necesario identificar todas las tablas que contienen restricciones referenciales y determinar en qué orden se enmascararán los datos, ya que las tablas principales deben enmascararse antes que las tablas secundarias correspondientes. Después de completar el proceso de enmascaramiento, no debemos olvidar comprobar si se mantuvo la integridad referencial.
Paso 5: Hacer que el proceso de enmascaramiento sea repetible.
Realizar ajustes en un proyecto particular o simplemente cambios generales dentro de la organización puede dar lugar a la modificación de los datos sensibles y la creación de nuevas fuentes de datos, lo que requiere repetir el proceso de enmascaramiento.
Existen casos en los que el enmascaramiento de datos puede ser un esfuerzo de una sola vez, como en el caso de preparar un conjunto de datos de entrenamiento especializado que se utilizará durante unos meses para un proyecto pequeño. Pero si se desea una solución que sirva durante un tiempo prolongado, los datos pueden volverse obsoletos en algún momento. Por lo tanto, es necesario invertir tiempo y esfuerzo en formalizar el proceso de enmascaramiento para que sea rápido, repetible y lo más automatizado posible.
Se deben desarrollar un conjunto de reglas de enmascaramiento, como qué datos deben enmascararse. Identificar cualquier excepción o caso especial que pueda prever en este momento. Adquirir/construir scripts y herramientas automatizadas para aplicar estas reglas de enmascaramiento de manera consistente.
Seleccionar una solución de enmascaramiento de datos
Ya sea que trabajes con un proveedor de software de tu elección u optes por una solución lista para usar, el producto final debe seguir las mejores prácticas de enmascaramiento de datos.
- Ser no reversible, haciendo imposible ingeniería inversa de los datos falsos a sus valores auténticos.
- Proteger la integridad de la base de datos original y no hacerla inútil mediante cambios permanentes por error.
- Enmascarar datos no sensibles si es necesario para proteger la información sensible.
- Proporcionar una oportunidad para la automatización, ya que los datos cambiarán en algún momento y no querrás empezar desde cero cada vez.
- Generar datos realistas que mantengan la estructura y la distribución de los datos originales y satisfagan las restricciones empresariales.
- Ser escalable para acomodar cualquier fuente de datos adicional que quieras incorporar en la empresa.
- Cumplir con todas las regulaciones aplicables, como HIPAA y GDPR, y las políticas internas.
- Integrarse bien en los sistemas y flujos de trabajo existentes.
Desafíos del enmascaramiento de datos
Aquí hay una lista de desafíos que podrías enfrentar durante la implementación.
- Preservación del formato. La solución de enmascaramiento tiene que entender los datos y ser capaz de preservar su formato original.
- Preservación de género. La metodología seleccionada de enmascaramiento de datos tiene que ser consciente del género al enmascarar los nombres de las personas. De lo contrario, la distribución de género dentro del conjunto de datos se verá alterada.
- Integridad semántica. Los valores falsos generados tienen que seguir las reglas empresariales que restringen diferentes tipos de datos. Por ejemplo, los salarios tienen que estar dentro de un rango específico, y los números de seguridad social tienen que seguir un formato predeterminado. Esto también es cierto para mantener la distribución geográfica de los datos.
- Unicidad de datos. Si los datos originales tienen que ser únicos, como el número de identificación del empleado, la técnica de enmascaramiento de datos tiene que suministrar un valor único.
- Equilibrar seguridad y usabilidad. Si los datos están demasiado enmascarados, pueden volverse inútiles. Por otro lado, si no están suficientemente protegidos, los usuarios pueden obtener acceso no autorizado.
- Integrar los datos en los flujos de trabajo existentes puede ser muy inconveniente para los empleados al principio, ya que están acostumbrados a trabajar de cierta manera, que actualmente está siendo interrumpida.
¿Cómo mantener datos enmascarados después de la implementación?
Tus esfuerzos no se detienen cuando los datos confidenciales están enmascarados. Todavía se necesita mantenerlos con el tiempo. Estos son los pasos que ayudarán en esta iniciativa:
- Establecer políticas y procedimientos que rijan los datos enmascarados. Esto incluye determinar quién está autorizado a acceder a estos datos y en qué circunstancias, y para qué propósitos sirve este dato (por ejemplo, pruebas, informes, investigación, etc.).
- Capacitar a los empleados sobre cómo utilizar y proteger estos datos.
- Auditar y actualizar regularmente el proceso de enmascaramiento para asegurarse de que siga siendo relevante.
- Monitorear los datos enmascarados en busca de cualquier actividad sospechosa, como intentos de acceso no autorizados y violaciones de seguridad.
- Realizar copias de seguridad de los datos enmascarados para asegurarse de que sean recuperables.
Pensamientos finales
El enmascaramiento de datos protegerá tus datos en entornos no productivos, permitirá compartir información con contratistas y ayudará con el compliance. Se puede adquirir y desplegar una solución de obfuscación de datos por sí mismo si se tiene un departamento de TI y se controlan los flujos de datos. Sin embargo, hay que tener en cuenta que una implementación incorrecta del enmascaramiento de datos puede llevar a consecuencias desagradables. Aquí hay algunas de las más prominentes:
- Dificultar la productividad. Las técnicas de enmascaramiento de datos seleccionadas pueden causar grandes retrasos innecesarios en el procesamiento de datos, lo que ralentizará a los empleados.
- Vulnerabilidad a violaciones de datos. Si los métodos de enmascaramiento de datos, o la falta de ellos, no protegen los datos confidenciales, habrá consecuencias financieras y legales que incluyen tiempo en prisión.
- Obtener resultados inexactos del análisis de datos. Esto puede suceder si los datos se enmascaran incorrectamente o demasiado. Los investigadores interpretarán mal el conjunto de datos experimental y llegarán a conclusiones defectuosas que llevarán a decisiones comerciales desafortunadas.
Por lo tanto, si una empresa no está segura de sus capacidades para ejecutar iniciativas de obfuscación de datos, es mejor contactar a un proveedor externo que ayudará a seleccionar las técnicas de enmascaramiento de datos correctas e integrar el producto final en los flujos de trabajo con interrupciones mínimas.
¡Manténte protegido!
¿Estás considerando implementar una solución de enmascaramiento de datos? ¡Ponte en contacto! Te ayudaremos a priorizar tus datos, construir una herramienta de obfuscación conforme y desplegarla sin interrumpir tus procesos comerciales.



