Idealmente, los robots del futuro reaccionarían en tiempo real a cualquier tarea relevante que un usuario pudiera describir en lenguaje natural. Particularmente en entornos humanos abiertos, puede ser importante que los usuarios finales personalicen el comportamiento del robot en tiempo real, ofreciendo correcciones rápidas (“detente, mueve el brazo un poco hacia arriba”) o especificando restricciones (“empuja ese objeto a la derecha”). Además, el lenguaje en tiempo real podría facilitar que las personas y los robots colaboren en tareas complejas y de largo plazo, con personas guiando de forma iterativa e interactiva la manipulación del robot con retroalimentación ocasional del lenguaje.

Sin embargo, hacer que los robots sigan vocabulario abierto plantea un desafío significativo desde una perspectiva de ML. Este es un entorno con una gran cantidad inherente de tareas, incluidas muchas pequeñas conductas correctivas. Las configuraciones de aprendizaje multitarea existentes hacen uso de datasets de aprendizaje por imitación o funciones de recompensa de aprendizaje de refuerzo complejo (RL) para impulsar el aprendizaje de cada tarea, y este esfuerzo significativo por tarea es difícil de escalar más allá de un pequeño conjunto predefinido. Por lo tanto, una pregunta aún sin respuesta en el entorno de vocabulario abierto es: ¿cómo podemos escalar la recopilación de datos de robots para incluir no docenas, sino cientos de miles de comportamientos en un entorno, y cómo podemos conectar todos estos comportamientos con el lenguaje natural que el usuario final realmente podría proporcionar?
En “Lenguaje Interactivo”, presentamos un marco de aprendizaje de imitación a gran escala para producir robots condicionales por lenguaje de vocabulario abierto en tiempo real. Después de entrenarlos con este enfoque, encontramos que una política individual es capaz de abordar más de 87,000 instrucciones únicas (un orden de magnitud mayor que los trabajos anteriores), con una tasa de éxito promedio estimada del 93.5%. También nos complace anunciar el lanzamiento de Language-Table, el conjunto de datos de robots con anotaciones de idioma más grande disponible, que esperamos impulse más investigaciones centradas en robots controlables por idioma en tiempo real.
| Robots guiados con lenguaje en tiempo real. |
Robots controlables por lenguaje en tiempo real
La clave de este enfoque es una receta escalable para crear grandes y diversos conjuntos de datos de demostración de robots condicionados por lenguaje. A diferencia de las configuraciones anteriores que definen todas las habilidades por adelantado y luego recopilan demostraciones seleccionadas para cada habilidad, se recopilan datos continuamente en varios robots sin reinicios ni calibraciones entre tareas. Todos los datos, incluidos los datos de fallas (p. ej., derribar bloques de una mesa), pasan por un proceso de reetiquetado del lenguaje en retrospectiva para ser emparejado con el texto. Aquí, los anotadores miran videos largos de robots para identificar tantos comportamientos como sea posible, marcan cuándo comenzó y terminó cada uno, y usan lenguaje natural de forma libre para describir cada segmento. Es importante destacar que, a diferencia de las instrucciones previas que siguen a las configuraciones, todas las habilidades utilizadas para el entrenamiento surgen de abajo hacia arriba a partir de los datos en sí, en lugar de que los investigadores las determinen por adelantado.
El enfoque y arquitectura de aprendizaje son intencionalmente sencillos. La política de robots es un transformador de atención cruzada, que mapea video y texto de 5 Hz a acciones de robots de 5 Hz, utilizando un objetivo de clonación conductual de aprendizaje supervisado estándar sin pérdidas auxiliares. En el momento de la prueba, se pueden enviar nuevos comandos hablados a la política (a través de dictado a texto) en cualquier momento hasta 5hz.
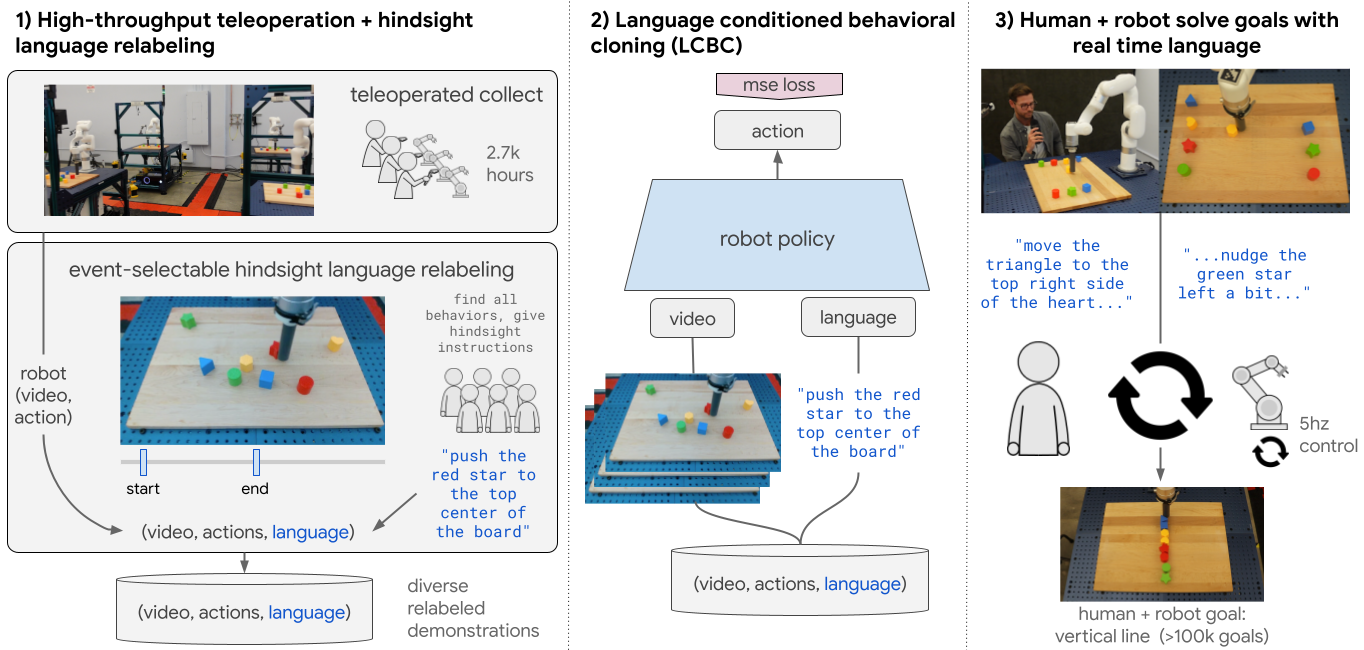 |
| Lenguaje interactivo: un sistema de aprendizaje por imitación para producir robots controlables por lenguaje en tiempo real. |
Lanzamiento de código abierto: Language-Table Dataset y Benchmark
Este proceso de anotación permitió recopilar el conjunto de datos de Language-Table, que contiene más de 440,000 demostraciones reales y 180,000 demostraciones simuladas del robot realizando un comando de lenguaje, junto con la secuencia de acciones que el robot realizó durante la demostración. Este es el conjunto de datos de demostración de robot condicionado por lenguaje más grande de su tipo, por orden de magnitud. Language-Table viene con un punto de referencia de aprendizaje de imitación simulado que se usa para realizar la selección de modelos y que se puede usar para evaluar nuevas instrucciones siguiendo arquitecturas o enfoques.
| Dataset | # Trayectorias (k) | # Único (k) | Acciones Físicas | Real | Disponible |
| Demostraciones episódicas |
|||||
| BC-Z | 25 |
0.1 |
✓ | ✓ | ✓ |
| SayCan | 68 |
0.5 |
✓ | ✓ |  |
| Playhouse | 1,097 |
779 |
|
|
|
| Etiquetado retrospectivo del lenguaje | |||||
| BLOCKS | 30 |
n / a | |
|
✓ |
| LangLFP | 10 |
n / a | ✓ | |
|
| LOREL | 6 |
1.7 |
✓ | ✓ | ✓ |
| CALVIN | 20 |
0.4 |
✓ | |
✓ |
| Language-Table (real + simulador) | 623 (442 + 181) | 206 (127 + 79) | ✓ | ✓ | ✓ |
| Se comparó Language-Table con conjuntos de datos de robots existentes, destacando proporciones de datos de robots simulados (rojo) o reales (azul), la cantidad de trayectorias recopiladas y la cantidad de tareas únicas descriptibles por lenguaje. |
Comportamientos lingüísticos aprendidos en tiempo real
 |
| Ejemplos de instrucciones de horizonte corto que el robot es capaz de seguir, muestreados aleatoriamente del conjunto completo de más de 87,000. |
| Instrucción de horizonte corto | Éxito |
| (87,000 más…) | … |
| empuja el triángulo azul hacia la esquina superior izquierda | 80,0% |
| separa la estrella roja y el círculo rojo | 100,0% |
| empuja el corazón amarillo un poco a la derecha | 80,0% |
| coloca la estrella roja sobre el cubo azul | 90,0% |
| apunta tu brazo hacia el triángulo azul | 100,0% |
| empuja el grupo de bloques un poco a la izquierda | 100,0% |
| Promedio sobre 87k, IC 95% | 93,5% +- 3,42% |
| Intervalo de confianza (IC) del 95% sobre el éxito promedio de una política individual de lenguaje interactivo sobre 87,000 instrucciones únicas en lenguaje natural. |
Se descubrió que surgieron nuevas capacidades interesantes cuando los robots pueden seguir el lenguaje en tiempo real. Se mostró que los usuarios pueden guiar a los robots a través de secuencias complejas de largo plazo usando solo lenguaje natural para resolver objetivos que requieren varios minutos de control preciso y coordinado (p. ej., “hacer una cara sonriente con los bloques con ojos verdes” o “colocar todos los bloques en una línea vertical”). Debido a que el robot está entrenado para seguir un lenguaje de vocabulario abierto, vemos que puede reaccionar a un conjunto diverso de correcciones verbales (p. ej., “empujar la estrella roja ligeramente hacia la derecha”) que, de lo contrario, podrían ser difíciles de enumerar por adelantado.
 |
| Ejemplos de objetivos a largo plazo alcanzados bajo la guía del lenguaje humano en tiempo real. |
Finalmente, vemos que el lenguaje en tiempo real permite nuevos modos de recopilación de datos de robots. Por ejemplo, un solo operador humano puede controlar cuatro robots simultáneamente utilizando solo el lenguaje hablado. Esto tiene el potencial de ampliar la recopilación de datos de robots en el futuro sin requerir la atención humana exclusiva para cada robot.
 |
| Un operador que controla varios robots a la vez con lenguaje hablado. |
Conclusión
Si bien actualmente se limita a una mesa con un conjunto fijo de objetos, Interactive Language muestra evidencia inicial de que el aprendizaje por imitación a gran escala puede producir robots interactivos en tiempo real que siguen los comandos del usuario final de forma libre. Se ha liberado el código de Language-Table, el conjunto de datos de demostración de robots del mundo real condicionado por lenguaje más grande de su tipo y un punto de referencia simulado asociado, para estimular el progreso en el control del lenguaje en tiempo real de los robots físicos. Creemos que la utilidad de este conjunto de datos no solo puede limitarse al control de robots, sino que puede proporcionar un punto de partida interesante para estudiar la predicción de video condicionada por el lenguaje y la acción, el modelado del lenguaje condicionado por video de robot o una serie de otras preguntas activas interesantes en el contexto más amplio de ML.



