Introducción
Elasticsearch es una plataforma de búsqueda con capacidades de búsqueda rápida. Es un motor de búsqueda basado en Lucene desarrollado en Java pero admite clientes en varios lenguajes como Python, C#, Ruby y PHP. Toma datos no estructurados de múltiples fuentes como entrada y los almacena en un formato estructurado que resulta óptimo para las búsquedas de idiomas.
Como se mencionó anteriormente, Elasticsearch se enfoca en las capacidades y características de búsqueda. Es útil para buscar múltiples tipos de datos. Tiene una arquitectura distribuida que permite la búsqueda y el análisis casi en tiempo real de grandes volúmenes de datos.
La capacidad de escalar de una máquina a cientos de máquinas la distingue de muchas otras herramientas. Un clúster de búsqueda con todas las funciones es fácil de ejecutar, aunque requiere un alto grado de experiencia. Además de los usos orientados a la búsqueda, Elasticsearch también es útil para almacenar datos que requieren agruparse por múltiples dimensiones. Se utiliza para registros de métricas, seguimientos y muchos otros datos de series temporales, por mencionar algunos ejemplos de su uso analítico.
AWS Elasticsearch
Amazon Elasticsearch Service o AWS Elastic search ahora se llama Amazon OpenSearch Service. Amazon OpenSearch es compatible con OpenSearch y Legacy Elasticsearch OSS. Al crear clústeres, los usuarios tienen la opción de elegir un motor de búsqueda. Existe una amplia compatibilidad entre OpenSearch y Elasticsearch OSS versión 7.10, que también es la versión final de este software de código abierto. OpenSearch es un motor de búsqueda de código abierto que ofrece funciones de herramientas de análisis para el análisis de registros en tiempo real y la supervisión de aplicaciones.
Los conceptos básicos detrás de Elasticsearch
Es fundamental comprender algunos conceptos clave. A continuación se muestra un glosario de varios componentes de Elasticsearch que será necesario comprender.
1) Documentos: antes de que entendamos “documentos”, veamos el término más utilizado llamado JSON. También es un formato global para el intercambio de datos de Internet. Para comprender esto, podemos comparar documentos con filas en una base de datos relacional que representa la entidad que estamos buscando.
Sin embargo, aquí los documentos no se limitan a textos sin formato, sino que incluyen datos estructurados, codificados en JSON. Cada documento tiene una identificación única y un tipo de datos. Estos detalles son importantes para determinar el tipo de datos del documento.
2) Índices: múltiples documentos con propiedades similares forman un índice. Curiosamente, también es la entidad de nivel superior contra la cual ejecutar una consulta en Elasticsearch. Los documentos del registro están lógicamente relacionados. Un índice está representado por un nombre que lo identifica durante la indexación y otras operaciones.
3) Índice invertido: el mecanismo de búsqueda sobre el que funcionan los motores. Los datos mapeados se almacenan aquí (contenido para colocar en el documento). Tenga en cuenta que estas cadenas no se almacenan directamente, sino que dividen el documento hasta el nivel de un elemento de búsqueda específico.
El proceso continúa y asigna cada uno de estos elementos de búsqueda a los documentos en los que aparecen. Esto permite búsquedas rápidas de texto completo incluso para grandes volúmenes de datos.
Elasticsearch – Conceptos de backend
Varios componentes de Elasticsearch están ocultos o se pueden etiquetar como componentes de backend.
Se enumeran a continuación:
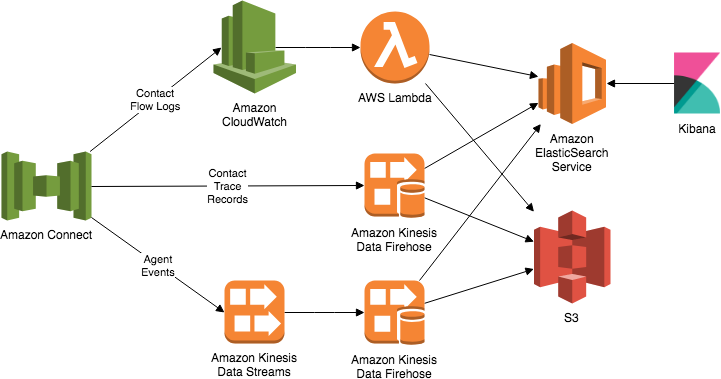
Fuente: aws.amazon.com
1. Grupo: un clúster se refiere a un grupo de múltiples nodos que están conectados. Aquí, Elasticsearch distribuye tareas y rastrea e indexa todos los nodos en el clúster.
2. Nodo: un nodo es un servidor en un clúster. Es el nodo donde se almacenan los datos y se lleva a cabo el proceso de indexación y recuperación del clúster. Hay muchas formas de configurar nodos para Elasticsearch.
- Nodo Maestro: este tipo de nodo actúa como la sala de control del clúster de Elasticsearch porque controla todas las operaciones, como la creación o eliminación de un índice o la adición o eliminación de nodos.
- Nodo de Datos: este nodo almacena y realiza operaciones relacionadas con los datos, como la agregación de datos.
- Nodo Cliente: este nodo envía solicitudes a los nodos apropiados. Tomemos un ejemplo; envía solicitudes de clúster al nodo principal y cualquier solicitud de datos a los nodos.
3. Fragmentos: como se mencionó anteriormente, el índice se divide en varias partes llamadas “fragmentos”. Cada fragmento es un índice independiente, totalmente funcional y se puede alojar en cualquier nodo del clúster. Los documentos en el índice se distribuyen en diferentes fragmentos. Estos fragmentos se envían a diferentes nodos, lo que crea una redundancia que es muy útil para proteger contra fallas de hardware y pérdida de datos. También aumenta la capacidad de consulta.
4. Réplicas: las réplicas son copias del fragmento de datos principal. Cada documento en el índice es parte de un fragmento principal. Como se explicó anteriormente, las réplicas crean copias de datos para evitar una situación de falla de hardware. También aumenta la capacidad de respuesta a las solicitudes.
Habilidades
Comprendamos las principales capacidades de Elasticsearch:
1. Motor de búsqueda: el punto de venta único de Elasticsearch permite una fácil búsqueda de texto completo. Esta función no se encontraba en los sistemas de administración de bases de datos SQL tradicionales porque carecían de capacidades de motor de búsqueda de texto completo para datos voluminosos.
2. Motor de análisis: Elasticsearch también atribuye mucha popularidad a su uso de análisis. Popularmente utilizado para análisis de registros y datos de partición numérica, como matrices de rendimiento. También permite la agregación de datos (consultas de agregación de Elasticsearch), lo que mejora la visualización de datos.
3. Diseño arquitectónico escalable: gracias a su arquitectura distribuida, Elasticsearch tiene una capacidad integrada para escalar a múltiples servidores. También puede almacenar datos en petabytes. Esto a menudo se ve en que los sistemas distribuidos son complejos, pero no aquí en Elasticsearch. La capacidad de escalar es mucho más fácil que la mayoría de los otros sistemas. Elasticsearch también replica automáticamente los datos en situaciones de falla del nodo, lo que ayuda a prevenir la pérdida de datos.
4. La elección de inversión correcta: el mecanismo de Elasticsearch es fácil de entender, especialmente cuando se trata de conjuntos de datos pequeños. Tiene una API común que se integra bien con otras herramientas como Logstash para enviar datos a Elasticsearch o Kibana para visualización de datos. Una curva de aprendizaje más corta y estas capacidades facilitan comenzar con Elasticsearch, lo que aumenta la productividad.
5. API bien documentada: este es otro punto que ha llevado a su creciente popularidad. Los desarrolladores pueden aprovechar la disponibilidad de las API de integración. Además, Elasticsearch proporciona bibliotecas de clientes compatibles para muchos lenguajes de programación como Java, JavaScript, PHP, etc., lo que facilita el proceso de integración para los desarrolladores.
Funcionamiento de Elasticsearch
El propósito principal de Elasticsearch es recibir y administrar datos semiestructurados. Este es un índice invertido administrado por la API de Apache que sirve como estructura de datos principal utilizada por Elasticsearch.
Debes estar preguntándote qué es un “índice invertido”. ¡Sigue leyendo para obtener las respuestas!
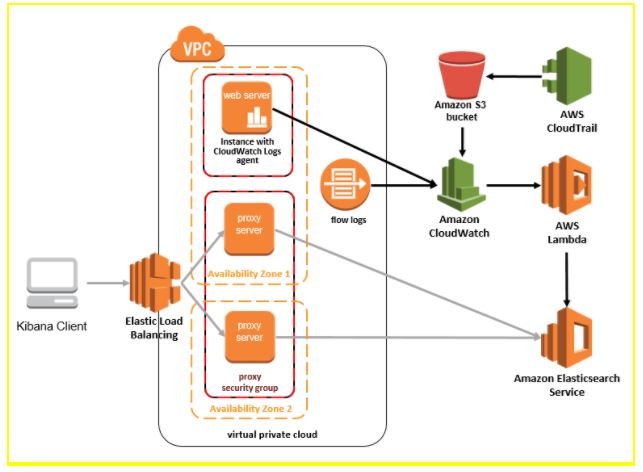
Fuente: aws.amazon.com
El mapeo de cada token único a una lista dada de documentos que contienen esa palabra es un índice invertido. Este proceso hace que la identificación de documentos utilizando una palabra clave determinada sea un proceso rápido. Hay varias particiones llamadas “fragmentos” en las que se almacena la información del índice. Elasticsearch no solo puede distribuir y asignar fragmentos dinámicamente a los nodos en un clúster, sino también replicarlos. Esto proporciona flexibilidad al proceso de distribución de datos.
La distribución de copias de fragmentos primarios a diferentes nodos de clúster proporciona una función de redundancia. Estos fragmentos primarios se usan durante las operaciones de índice, mientras que ambos tipos de fragmentos se usan cuando se ejecutan consultas de búsqueda. El rendimiento de la ejecución de consultas se mejora con múltiples nodos y réplicas.
Casos de uso
Hay algunos casos de uso básicos para Elasticsearch:
1. Aplicaciones de búsqueda: esto es especialmente importante para los sitios web que dependen de una plataforma de búsqueda para acceder, recuperar e informar datos.
2. Búsqueda en el sitio web: Elasticsearch es muy importante para proporcionar consultas de búsqueda precisas y rápidas para sitios web que almacenan grandes cantidades de datos. Ahora ha establecido un bastión en la búsqueda web.
3. Búsqueda empresarial: Elasticsearch también permite la búsqueda en toda la empresa, como la búsqueda de documentos, la búsqueda de productos de comercio electrónico, etc. También se ha convertido en la solución de búsqueda más confiable para muchos sitios web.
4. Análisis de registros: como se mencionó anteriormente, Elasticsearch es una herramienta común para analizar datos de registro casi en tiempo real. No solo eso, sus capacidades escalables y su conocimiento operativo esencial lo convierten en una opción popular.
5. Análisis de seguridad: el análisis de seguridad es otro dominio importante en el que Elasticsearch juega un papel muy importante. Analiza los registros de acceso y registros similares relacionados con los sistemas de seguridad utilizando la pila ELK, que muestra un análisis completo.
6. Análisis de negocios: muchas funciones integradas en la pila ELK también la convierten en una popular herramienta de análisis empresarial. Sin embargo, adquirir conocimientos profundos sobre la implementación de estas herramientas puede llevar más tiempo.
Ventajas
Estos son algunos de los beneficios enumerados:
1. Estándares de alto rendimiento: Elasticsearch puede procesar simultáneamente grandes volúmenes de datos, lo que proporciona resultados de consulta de búsqueda rápidos.
2. Desarrollo de aplicaciones: admite múltiples lenguajes de programación como Java, Python, PHP, etc., lo que lo convierte en una opción popular para los desarrolladores para el desarrollo de aplicaciones.
3. Velocidad de operación rápida: las operaciones de Elasticsearch, como la lectura y la escritura, son tan rápidas como un abrir y cerrar de ojos, lo que permite su uso para casos de uso casi en tiempo real, como el monitoreo de aplicaciones.
5. Herramientas adicionales: Kibana es una herramienta de visualización e informes integrada con Elasticsearch. Elasticsearch también proporciona integración con Beats y Logstash, lo que permite cargar transformaciones de datos de origen en clústeres. Hay muchos complementos disponibles que pueden mejorar la funcionalidad de las aplicaciones.
Conclusión
Elasticsearch también atribuye mucha popularidad a su uso de análisis, popularmente utilizado para análisis de registros y datos de partición numérica, como matrices de rendimiento. También permite la agregación de datos (consultas de agregación de Elasticsearch), lo que mejora la visualización de datos. Diseño arquitectónico escalable: Elasticsearch tiene una capacidad integrada para escalar a múltiples servidores gracias a su arquitectura distribuida. También puede almacenar datos en petabytes, esto a menudo se ve en que los sistemas distribuidos son complejos, pero no aquí en Elasticsearch.
- Elasticsearch se enfoca en las capacidades y características de búsqueda. Es útil para buscar múltiples tipos de datos. Tiene una arquitectura distribuida que permite la búsqueda y el análisis casi en tiempo real de grandes volúmenes de datos.
- Las decisiones se toman automáticamente, lo que garantiza una API de gestión fluida. La capacidad de escalar es mucho más fácil que la mayoría de los otros sistemas. Elasticsearch también replica automáticamente los datos en situaciones de falla del nodo, lo que ayuda a prevenir la pérdida de datos.
- Amazon Elasticsearch Service o AWS Elastic search ahora se llama Amazon OpenSearch Service. Amazon OpenSearch es compatible con OpenSearch y Legacy Elasticsearch OSS. OpenSearch es un motor de búsqueda de código abierto que ofrece funciones de herramientas de análisis para el análisis de registros en tiempo real y la supervisión de aplicaciones.



