En una planta de cemento una mala decisión no es teórica. Se traduce en material desperdiciado. A veces toneladas.
El equipo con el que trabajamos era responsable del diseño de mezcla cruda: encontrar las proporciones correctas de clínker, yeso, piedra caliza y otros componentes para producir un cemento que cumpla con las especificaciones de resistencia a la compresión. Su proceso era iterativo por naturaleza. Se diseña la mezcla, se producen probetas y se espera. Un día. Tres días. Siete. Veintiocho. Solo entonces sabes si la mezcla funcionó.
Si no funcionó empiezas de nuevo.
Ese ciclo no es solo lento. Es costoso. En un contexto de I+D donde se están evaluando múltiples formulaciones en paralelo el tiempo de espera se convierte en el principal cuello de botella. La pregunta que surgió fue directa: ¿se puede estimar la resistencia antes de esperar?
El objetivo no era entrenar un modelo
Este punto vale la pena decirlo desde el principio porque cambia toda la lógica del proyecto.
El objetivo no era maximizar una métrica. Era reducir el número de pruebas físicas necesarias para validar una mezcla. El modelo era el medio. La decisión más rápida era el fin.
Esto parece obvio cuando se dice así, pero en la práctica la mayoría de los proyectos de ML industrial pierden este hilo muy pronto. Se quedan optimizando indicadores técnicos cuando el problema real es que el ingeniero de planta no confía en el resultado o no sabe cuándo usarlo.
Todo proyecto de ML bien diseñado empieza respondiendo preguntas de fondo antes de tocar datos. Preguntas como estas:
-
- ¿Qué problema resuelves exactamente y qué decisión concreta impacta ese modelo?
-
- ¿De dónde vienen los datos y cómo se mantienen actualizados?
-
- ¿Qué tipo de modelo exige la naturaleza del problema?
-
- ¿Qué métrica define el éxito y con qué nivel de error es aceptable?
-
- ¿Qué restricciones condicionan el sistema — regulatorias, operativas, de adopción?
-
- ¿Cómo se implementa el modelo y quién lo mantiene en producción?
Si no tienes respuesta clara para cada una de estas preguntas antes de entrenar, el modelo probablemente resuelva el problema equivocado. En nuestra metodología de diseño de proyectos de ML profundizamos en cómo trabajar estas preguntas antes de escribir código.
En este caso el equipo de I+D necesitaba velocidad para explorar formulaciones y control sobre la calidad del resultado. Esas dos cosas no siempre van en la misma dirección. Ese fue el primer trade-off real del proyecto y apareció antes de escribir una sola línea de código.
La decisión técnica más importante no fue el algoritmo
Se usó regresión. Para quienes no están familiarizados con el término: una regresión es un tipo de modelo que predice un número continuo. En este caso predice exactamente cuántos PSI de resistencia tendrá una mezcla. La alternativa habría sido clasificación, que en vez de un número devuelve una categoría como “alta resistencia” o “baja resistencia”.
La razón para elegir regresión no fue técnica. Fue operativa.
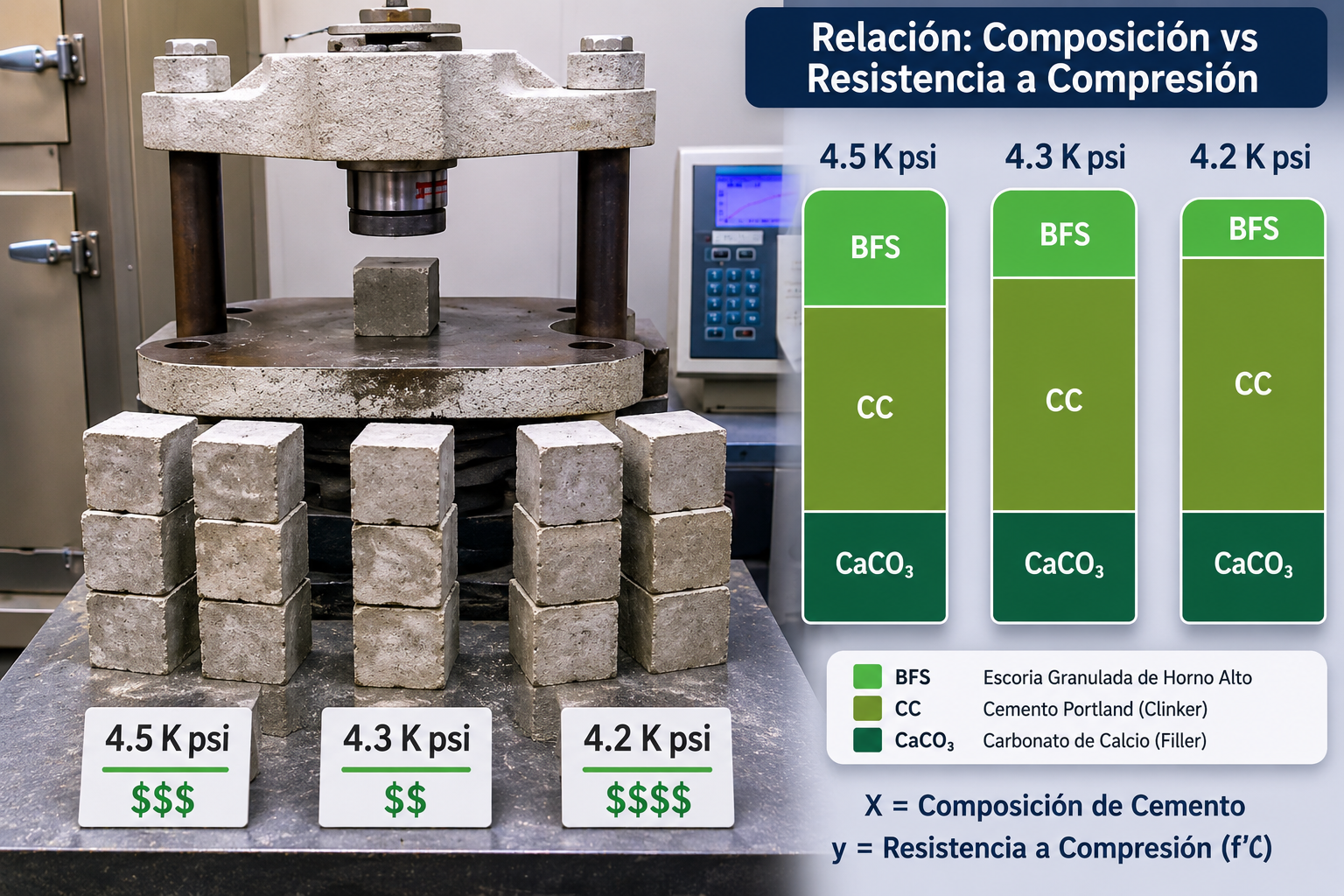
El equipo necesitaba un valor exacto de resistencia en PSI, no una etiqueta. La diferencia entre 4.200 PSI y 4.500 PSI tiene implicaciones concretas en el costo de los componentes y en el cumplimiento de especificaciones del producto. Una categoría no permite hacer ese ajuste fino. Por tanto el tipo de modelo se eligió desde el uso, no desde la técnica.
Después vino otra decisión igual de importante. Elegir entre modelos de mayor precisión o modelos interpretables.
En el benchmarking se compararon cuatro enfoques con sus resultados:
-
- Regresión Lineal: el punto de partida. Error alto pero sirve como referencia mínima obligatoria.
-
- Random Forest: buen balance entre precisión y explicabilidad. Muestra qué variables influyen más en el resultado.
-
- XGBoost: el de mayor precisión en las pruebas. Más difícil de explicar a alguien sin formación técnica.
-
- Red Neuronal: precisión similar a XGBoost pero con mayor costo de implementación y sin ventaja clara en este tipo de dato.
Se eligió Random Forest como modelo de producción. No porque tuviera el menor error. Sino porque en un entorno donde el ingeniero necesita explicar a su gerente por qué recomienda cambiar la proporción de yeso, la capacidad de señalar qué variables pesan más en la decisión vale más que unos puntos de diferencia en la métrica. Un modelo que nadie puede explicar termina siendo un modelo que nadie usa.
Los datos eran buenos, pero no perfectos
Los datos venían de pruebas reales de laboratorio. Eso es una ventaja significativa. Cada fila era una prueba física con medición controlada. Sin embargo no todas las variables aportaban valor al modelo.
Algunas tenían varianza casi nula. Dicho en términos simples: eran variables que prácticamente no cambiaban entre una formulación y otra. Si algo no varía, no puede explicar por qué el resultado sí varía. Son datos que ocupan espacio sin aportar información.
Otras variables eran combinaciones matemáticas de otras columnas del mismo dataset, lo que introduce redundancia y puede confundir al modelo.
Aquí aparece un problema frecuente en equipos con experiencia técnica. El análisis exploratorio se trata como un checklist:
-
- Graficar distribuciones ✓
-
- Calcular correlaciones ✓
-
- Identificar valores faltantes ✓
-
- Documentar hallazgos ✓
Y luego se continúa. Pero no se decide nada.
El valor del análisis exploratorio no está en las gráficas. Está en las decisiones que produce. En este proyecto el resultado más importante del análisis fue una lista de variables eliminadas. Reducir ruido fue más valioso que agregar complejidad. Esa lección aplica a prácticamente cualquier proyecto de datos en industria.
El despliegue fue la decisión más subestimada
Aquí es donde muchos proyectos industriales fallan silenciosamente. El modelo existe, las métricas son razonables y aun así nadie lo usa seis meses después.
La razón habitual no es técnica. Es que el modelo requiere un flujo que interrumpe el trabajo del usuario. Una interfaz nueva que aprender. Un sistema desconectado de lo que ya se usa cotidianamente. Fricción, en una palabra.
En este proyecto se tomó una decisión deliberada: no construir nada nuevo. El ingeniero ya trabajaba en hojas de cálculo. Eso era punto de partida suficiente.
La arquitectura resultante fue simple por diseño:
-
- El usuario ingresa las proporciones de la mezcla en Google Sheets, la hoja de cálculo que ya conoce.
-
- Una función automatizada convierte esos datos y los envía al modelo.
-
- El modelo procesa la información y devuelve la resistencia estimada en segundos.
-
- El resultado aparece directamente en la misma hoja, sin pasos adicionales.
No hay instalaciones. No hay capacitación técnica. No hay una app nueva que aprender. El usuario hace exactamente lo que ya hacía y obtiene un resultado adicional que antes no tenía.
Este trade-off entre adopción y sofisticación es uno de los más frecuentes en proyectos industriales. La pregunta relevante no es qué arquitectura es más elegante. Es qué arquitectura el usuario va a usar mañana sin que nadie se lo recuerde. En entornos donde el cambio tecnológico genera resistencia institucional simplificar el despliegue es con frecuencia la decisión de mayor impacto.
El error del modelo no es solo una métrica
En la mayoría de los proyectos el error del modelo vive en una tabla de resultados. En proyectos industriales el error tiene consecuencias físicas.
Una predicción incorrecta puede llevar a aprobar una mezcla que no cumple especificaciones. El cemento se vende con características declaradas. Si el producto final no las cumple hay consecuencias directas: reclamos de clientes, responsabilidad sobre la obra, costos de remediación.
Además no todos los errores son equivalentes:
-
- Subestimar la resistencia lleva a descartar una mezcla que sí funcionaba. Consecuencia: desperdicio de material y tiempo.
-
- Sobreestimar la resistencia lleva a aprobar una mezcla que no cumple. Consecuencia: riesgo estructural y legal.
El sesgo del modelo importa tanto como su magnitud de error. Por eso el modelo no reemplaza el proceso de validación física. Lo acompaña. Permite descartar opciones antes de producirlas y priorizar qué mezclas vale la pena llevar a prueba. El valor no está en eliminar el proceso sino en hacer que ese proceso sea más eficiente.
Los límites del sistema son parte del diseño
El modelo usa composición química como input. Eso cubre una parte importante de la variabilidad en la resistencia pero no toda.
Factores que el modelo no incluye:
-
- Calidad del agua usada en planta
-
- Condiciones del proceso de molienda
-
- Temperatura de cocción del clínker
-
- Variaciones entre proveedores de materia prima
Si alguno de esos factores cambia el modelo puede perder validez sin que los números internos lo señalen de forma obvia.
Vale la pena distinguir entre un fallo técnico y un límite del sistema. Un fallo técnico es algo que se corrige mejorando el modelo. Un límite del sistema es una decisión de alcance: se eligió modelar la composición química porque era la información disponible y porque cubría suficientemente el problema de negocio. Comunicar ese límite al equipo de I+D fue parte del entregable. No como advertencia legal sino como información operativa. Esa honestidad hace que el sistema sea más durable en producción.
El resultado no es un modelo. Es una herramienta de decisión
Al final del proyecto el equipo de I+D no tenía un modelo. Tenía un flujo de trabajo modificado.
Podían explorar más formulaciones en el mismo tiempo. Podían priorizar con más criterio qué mezclas llevar a prueba física. Podían reducir el número de iteraciones antes de llegar a una formulación viable. El ciclo de veintiocho días no desapareció, pero se usaba de forma más selectiva.
Eso es lo que significa que un proyecto de ML tenga impacto en industria. No que el modelo tenga un indicador técnico alto. Sino que el flujo de trabajo del equipo cambie de forma medible.
El valor no estaba en el algoritmo. Estaba en las decisiones que ese algoritmo habilitó:
-
- Ajustar proporciones antes de producir
-
- Evitar pruebas físicas innecesarias
-
- Reducir desperdicio de material
-
- Acortar el ciclo de desarrollo de formulaciones
Si quieres ver el pipeline completo incluyendo el tratamiento de datos, el benchmarking de modelos y la arquitectura de despliegue, está documentado en detalle en el proyecto completo de predicción de resistencia del cemento.
Lo que no funcionó (y por qué fue la decisión correcta de todas formas)
El trade-off más difícil no fue técnico: fue convencer al equipo de usar el modelo y seguir haciendo las pruebas físicas en paralelo. La tentación fue hacer del modelo la única ruta para acelerar adopción. No se hizo, porque sin validación física el modelo pierde su fuente de verdad y envejece sin que nadie lo note. La adopción fue más lenta de lo esperado, pero el sistema resultó más robusto.
Lo que se sacrificó en ese proceso:
-
- Velocidad de adopción en las primeras semanas
-
- Claridad para atribuir resultados directamente al modelo durante el piloto
-
- Consistencia en el uso: algunos ingenieros lo consultaban antes de decidir, otros lo registraban después como formalidad
-
- La posibilidad de medir impacto limpio sin el ruido del proceso de transición
-
- Tiempo de gestión del cambio que no estaba en el alcance original del proyecto
¿Cómo se mide el éxito? Los KPIs que este tipo de proyecto debería reportar
Los números específicos de este proyecto son confidenciales, pero sí tiene sentido nombrar qué métricas instrumentar desde el diseño. Si no se definen antes del despliegue, es muy difícil demostrar impacto después.
-
- Reducción en pruebas físicas por formulación aprobada. La métrica central del proyecto
-
- Tasa de descarte anticipado. Qué porcentaje de mezclas que el modelo predijo como fallidas efectivamente lo fueron



